
In this article we posting part of the work “Video Synthesis with Diffusion Models” by Runway team: Patrick Esser, Johnathan Chiu, Parmida Atighehchian, Jonathan Granskog, Anastasis Germanidis.
Abstract
Text-guided generative diffusion models unlock powerful image creation and editing tools. While these have been ex- tended to video generation, current approaches that edit the content of existing footage while retaining structure require expensive re-training for every input or rely on error-prone propagation of image edits across frames.
In this work, we present a structure and content-guided video diffusion model that edits videos based on visual or textual descriptions of the desired output. Conflicts between user-provided content edits and structure representations occur due to insufficient disentanglement between the two aspects. As a solution, we show that training on monoc- ular depth estimates with varying levels of detail provides control over structure and content fidelity. Our model is trained jointly on images and videos which also exposes ex- plicit control of temporal consistency through a novel guid- ance method. Our experiments demonstrate a wide variety of successes; fine-grained control over output characteris- tics, customization based on a few reference images, and a strong user preference towards results by our model.
Introduction
Visual effects and video editing are ubiquitous in the modern media landscape. As such, demand for more in- tuitive and performant video editing tools has increased as video-centric platforms have been popularized. However, editing in the format is still complex and time-consuming due the temporal nature of video data. State-of-the-art ma- chine learning models have shown great promise in improv- ing the editing process, but methods often balance temporal consistency with spatial detail. Generative approaches for image synthesis recently ex- perienced a rapid surge in quality and popularity due to the introduction of powerful diffusion models trained on large- scale datasets.
Text-conditioned models, such as DALL-E 2 and Stable Diffusion, enable novice users to gen- erate detailed imagery given only a text prompt as input. Latent diffusion models especially offer efficient methods for producing imagery via synthesis in a perceptually com- pressed space. Motivated by the progress of diffusion models in image synthesis, we investigate generative models suited for inter- active applications in video editing. Current methods repurpose existing image models by either propagating edits with approaches that compute explicit correspondences [5] or by finetuning on each individual video [63]. We aim to cir- cumvent expensive per-video training and correspondence calculation to achieve fast inference for arbitrary videos.

We propose a controllable structure and content-aware video diffusion model trained on a large-scale dataset of un- captioned videos and paired text-image data. We opt to rep- resent structure with monocular depth estimates and content with embeddings predicted by a pre-trained neural network. Our approach offers several powerful modes of control in its generative process.
First, similar to image synthesis models, we train our model such that the content of inferred videos, e.g. their appearance or style, match user-provided images or text prompts (Fig. 1). Second, inspired by the diffusion process, we apply an information obscuring process to the structure representation to enable selecting of how strongly the model adheres to the given structure. Finally, we also adjust the inference process via a custom guidance method, inspired by classifier-free guidance, to enable control over temporal consistency in generated clips.
In summary, we present the following contributions:
- We extend latent diffusion models to video generation by introducing temporal layers into a pre-trained im-age model and training jointly on images and videos.
- We present a structure and content-aware model that modifies videos guided by example images or texts. Editing is performed entirely at inference time withoutadditional per-video training or pre-processing.
- We demonstrate full control over temporal, content and structure consistency. We show for the first time that jointly training on image and video data enables inference-time control over temporal consistency. For structure consistency, training on varying levels of de- tail in the representation allows choosing the desiredsetting during inference.
- We show that our approach is preferred over severalother approaches in a user study.
- We demonstrate that the trained model can be furthercustomized to generate more accurate videos of a spe- cific subject by finetuning on a small set of images.
Related Work
Controllable video editing and media synthesis is an active area of research. In this section, we review prior work in related areas and connect our method to these approaches.
Unconditional video generation
Generative adversarial networks (GANs) can learn to synthesize videos based on specific training data. These methods often struggle with stability during optimization, and produce fixed-length videos or longer videos where artifacts accumulate over time. Some works synthesize longer videos at high detail with a custom positional encoding and an adversarially-trained model leveraging the encoding, but training is still restricted to small-scale datasets. Autoregressive transformers have also been proposed for unconditional video generation. However, our focus is on providing user control over the synthesis process whereas these approaches are limited to sampling random content resembling their training distribution.
Diffusion models for image synthesis
Diffusion models (DMs) have recently attracted the attention of researchers and artists alike due to their ability to synthesize detailed imagery, and are now being applied to other areas of content creation such as motion synthesis and 3d shape generation.
Other works improve image-space diffusion by changing the parameterization, introducing advanced sampling methods, designing more powerful architectures, or conditioning on additional information. Text-conditioning, based on embeddings from CLIP or T5, has become a particularly powerful approach for providing artistic control over model output. Latent diffusion models (LDMs) perform diffusion in a compressed latent space reducing memory requirements and runtime. We extend LDMs to the spatio-temporal domain by introducing temporal connections into the architecture and by training jointly on video and image data.
Diffusion models for video synthesis
Recently, diffusion models, masked generative models, and autoregressive models have been applied to text-conditioned video synthesis. Similar to some works, we extend image synthesis diffusion models to video generation by introducing temporal connections into a pre-existing image model. However, rather than synthesizing videos, including their structure and dynamics, from scratch, we aim to provide editing abilities on existing videos. While the inference process of diffusion models enables editing to some degree, we demonstrate that our model with explicit conditioning on structure is significantly preferred.
Video translation and propagation
Image-to-image translation models, such as pix2pix, can process each individual frame in a video, but this produces inconsistency between frames as the model lacks awareness of the temporal neighborhood. Accounting for temporal or geometric information, such as flow, in a video can increase consistency across frames when repurposing image synthesis models. We can extract such structural information to aid our spatio-temporal LDM in text- and image-guided video synthesis. Many generative adversarial methods, such as vid2vid, leverage this type of input to guide synthesis combined with architectures specifically designed for spatio-temporal generation. However, similar to GAN-based approaches for images, results have been mostly limited to singular domains.
Video style transfer takes a reference style image and sta- tistically applies its style to an input video . In comparison, our method applies a mix of style and content from an input text prompt or image while being constrained by the extracted structure data. By learning a generative model from data, our approach produces semantically con- sistent outputs instead of matching feature statistics.
Text2Live allows editing input videos using text prompts by decomposing a video into neural layers . Once available, a layered video representationprovides consistent propagation across frames. SinFusion can generate variations and extrapolations of videos by optimiz- ing a diffusion model on a single video. Similarly, Tune-a-Video finetunes an image model converted to video generation on a single video to enable editing. However, expensive per-video training limits the practicality of these approaches in creative tools. We opt to instead train our model on a large-scale dataset permitting inference on any video without individual training.
Method
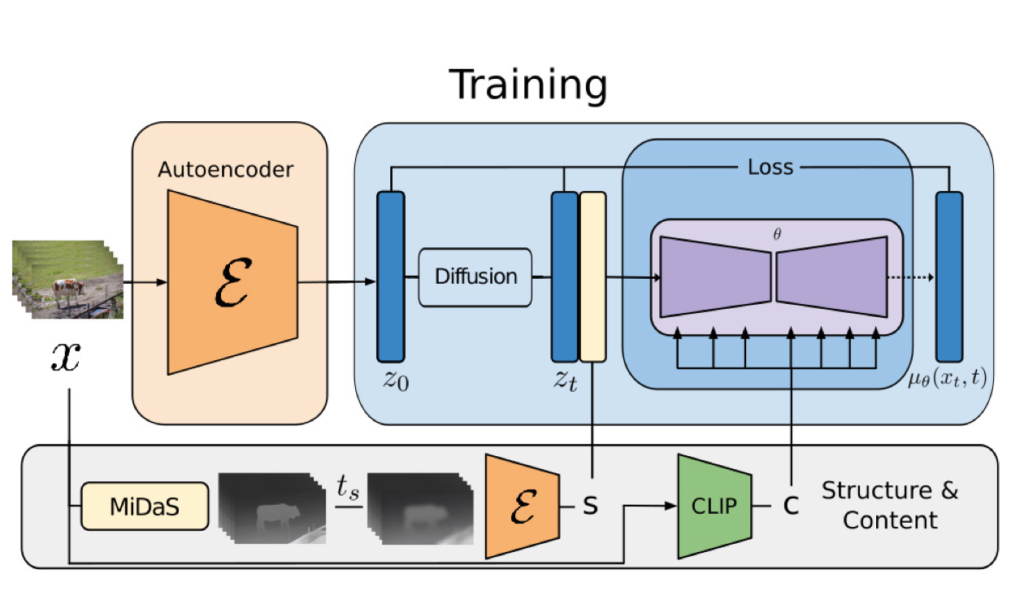
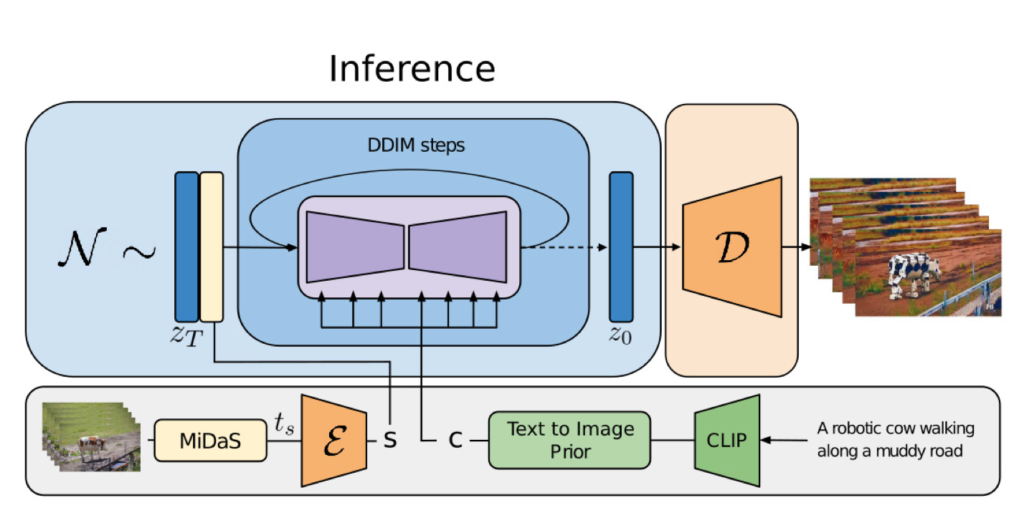
For our purposes, it will be helpful to think of a video in terms of its content and structure. By structure, we re- fer to characteristics describing its geometry and dynamics, e.g. shapes and locations of subjects as well as their tem- poral changes. We define content as features describing the appearance and semantics of the video, such as the colors and styles of objects and the lighting of the scene. The goal of our model is then to edit the content of a video while retaining its structure.
To achieve this, we aim to learn a generative model p(x|s,c) of videos x, conditioned on representations of structure, denoted by s, and content, denoted by c. We infer the shape representation s from an input video, and modify it based on a text prompt c describing the edit. First, we describe our realization of the generative model as a conditional latent video diffusion model and, then, we describe our choices for shape and content representations. Finally, we discuss the optimization process of Runway model in the work.
Read related articles: